
In this series, we dive into technologies and industries we’re excited about, going deep into their change drivers and stakeholders while exploring investment trends and opportunities through an early-stage lens.
Sector: Data infrastructure
In a sentence: The modern data infrastructure stack refers to the underlying technologies that pull data from data sources and siphon it throughout an organization for specific use cases — typically downstream business analytics (BI) and machine learning applications (AI/ML). When we refer to the modern data stack, we’re not only focused on underlying data infrastructure technologies; we’re also interested in new tools emerging within the BI and AI/ML categories that leverage the modern stack to drive business insights.
Size and scope: Data infrastructure is a near $200B market and is expected to grow exponentially over the next decade. Importantly, that number excludes any BI or AI/ML tools that build on the stack. In our view, this makes data infrastructure and its associated top-of-stack tools one of the most compelling categories to invest in.
Stakeholders: Generally, when we think about key stakeholders in the data infrastructure space, we’re most concerned with: 1) business leaders (CEOs, CFOs, CMOs), 2) internal business teams (sales, finance, marketing) that leverage data, and 3) the data scientists/data engineers themselves. All three sets of stakeholders are presently leveraging new capabilities in the data stack to power more pinpointed insights for their organizations.
Company leaders primarily leverage the data infrastructure stack to generate specific KPIs — in today’s world, being able to extract metrics quickly and make on-the-go changes is crucial for organizations to compete. Team members within traditional business functions leverage data to target top accounts or improve financial performance by analyzing historical results. And data teams themselves plug in at various points within the stack to improve machine learning models and enhance the time to value of these models (among many other things).
Change drivers: Three drivers fueled recent changes in the modern data stack and will continue to propel growth.
- First, the sheer amount of data that we have access to has exploded. Simply put, there’s a lot more data available at all times. Over the last two decades, SaaS businesses took off and generated tons of data across a variety of use cases, and web data similarly became highly accessible.
- Second, there are more users of this data within every organization. Businesses no longer have one data analytics team that generates one report focusing on one type of data or a handful of static metrics. Teams across different business units need more consistent access to data to measure KPIs and answer function-specific questions very quickly.
- Third, there are more use cases for data. Data’s value becomes imperative even at the highest levels of an organization, with CEOs/CFOs/CMOs demanding quick innovation/iteration to drive efficiency and value for their businesses. At the executive level, the use cases for the data we have today are limitless.
These tailwinds have fueled strong dynamics in data/cloud computing in both the public and private markets. In the public market, five of the seven largest historical software IPOs were in the data infrastructure space.

The private markets have similarly followed suit, with private cloud business multiples and growth rates skyrocketing throughout 2020 (despite pandemic headwinds), and PE/VC capital invested growing 10x YoY from 2019–2020. This growth is expected to continue rapidly throughout the coming years.
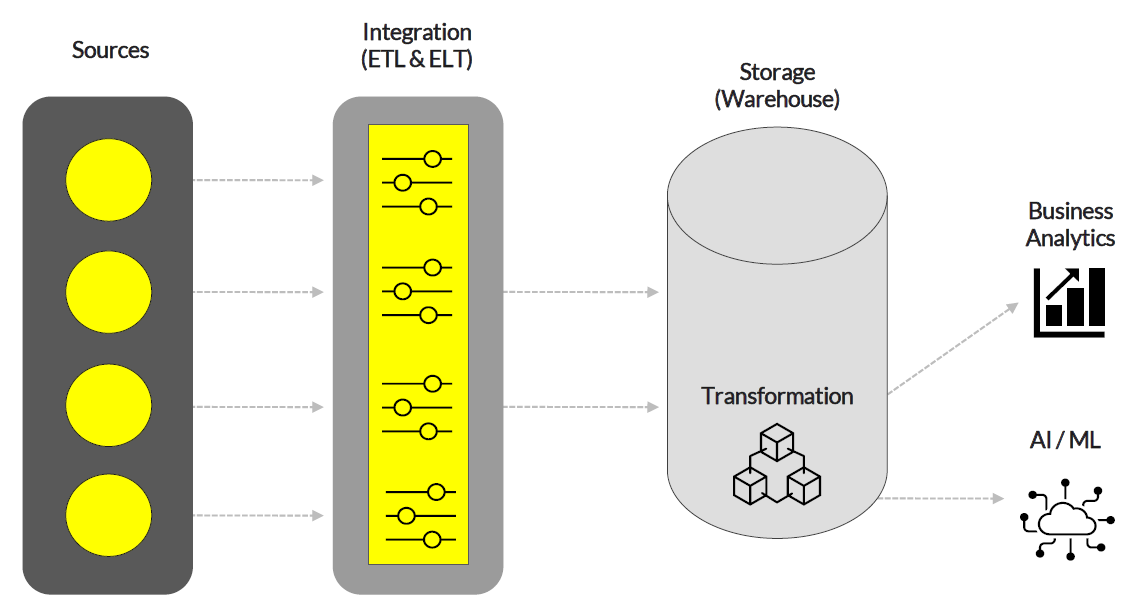
The modern data stack: Within the modern data stack, there are four key layers:
- Sources of collected data (Stripe, CRM, SQL, Segment, Shopify, Google Ads, and more)
- Integration tools (ETL/ELT), which extract data from sources and process it through data pipelines into one set for insights
- The storage/management layer, which includes data warehouses/lakes — the central location where processed data is stored. The warehousing layer also includes transformation tools, which turn raw data into clean data for specific use cases
- Business analytics (BI) and AI/ML tools sit at the top of the stack and often plug directly into the data warehouse, allowing members of organizations to drive functional insights
New capabilities in the stack: In recent years, several key technological shifts occurred in the data stack, setting a strong foundation for future innovation.
- Warehousing: Data storage became significantly cheaper and virtually all businesses shifted to cloud-based solutions
- ETL/ELT: Extract, Transform, Load (the key process that occurred within the integration layer) became Extract, Load, Transform, as data no longer needed to be trimmed down through to save storage costs before entering the warehouse. And reverse ETL tools emerged on the warehouse back-end with specific use cases for BI teams
- Transformation: In conjunction with ELT, data manipulation moved into the warehousing layer
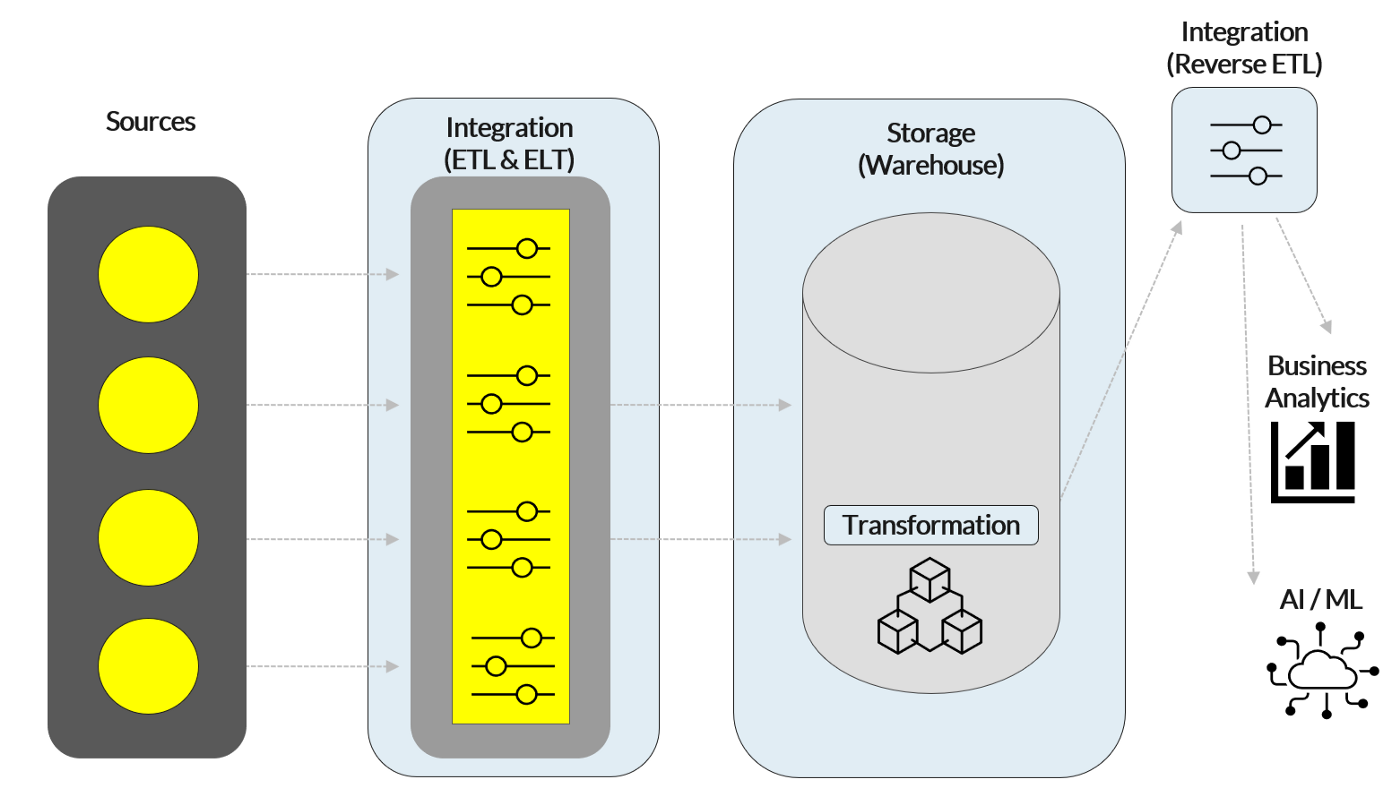
Today’s data warehousing model can handle an infinite amount of computing thrown at it. Furthermore, changes to integration and transformation let teams access data in a uniform manner, allowing them to streamline and automate data analysis more efficiently for their specific use cases. With these new capabilities, the question then becomes — what tools will be built on top of the modern stack that leverage these new capabilities?
We see four areas of opportunity:
- Data privacy / quality / governance
- Self-serve business analytics tools
- Next-gen go-to-market platforms
- ML workflow tools (ML-ops tools)
Data privacy/quality/governance: The fundamental opportunity within data privacy lies within the fact that tech companies were built to collect data, but lack the ability to store it safely. There’s a massive gap between where privacy policies are today and where they need to be. Despite companies reportedly spending north of $100B on IT security, we are continuing to see record years of data breach activity. A new subset of companies is emerging to fill the privacy gap and allow enterprises to more responsibly capture user data.
Within the broad landscape of data privacy, we are particularly excited about data lineage tools and privacy & consent applications (both B2B and B2C), most of which sit in the metadata layer and above, slightly further from source data than the traditional cataloging and classification tools. We see significant market opportunities in both of these categories. Within data lineage, specifically, most solutions today are very early and companies continue to lack technology to identify dirty data. Within privacy, the market today is also early, standing at $1.5B, with a 42% CAGR expected in the coming years. Data privacy is increasingly becoming part of public dialogue and both businesses and consumers will continue to devote resources to improving it.
Self-serve business analytics: At LH, we recently invested in Peel Insights, an analytics automation tool specifically for Shopify stores and e-commerce metrics. We’re believers in the overall e-commerce enablement category and view Peel as well-primed to succeed in helping online businesses scale through metric extraction. Beyond these verticalized BI solutions, a growing category of industry-agnostic self-serve BI tools is emerging through companies like Trace, Transform, and Supergrain, businesses that leverage the innovation that transformation tools like dbt pioneered — building within the warehousing layer such that all downstream BI tools can plug directly into one source. The primary use case for these three businesses is unified metric extraction: the creation of a singular metrics layer that can become the sole source of truth for metric definition and extraction across all business functions. Every company seeks to define KPIs, and yet, no key solution exists today that solves metric extraction in a unified way. We’re excited about the potential for the metrics layer and any businesses building toward it.
Next-gen GTM platforms: We define GTM in four buckets: sales enablement, RevOps & customer success, community engagement, and marketing. We recently led the seed in Variance, a sales enablement tool supporting the product-led sales motion. Like the Variance founders, we believe that product-led sales is here to stay, but requires a combination of intuitive software that unifies customer data for reps AND a more traditional enterprise motion. Beyond pure sales, we are excited about all tools within the four GTM categories that leverage the modern stack to its full potential. Many solutions across the GTM functions are increasingly building on reverse ETL solutions like Census or Grouparoo to drive operational analytics and generate a consistent view of the customer for reps. At LH, we recognize that GTM reps today increasingly face nonlinear customer workflows and must manage customer data across countless channels — making it ever more difficult to drive insights that lead to revenue conversion opportunities. We’re excited about businesses building across the GTM motion and believe there’s a clear need for new tooling to ease the experience of reps in each GTM function.

ML-ops tools: Machine learning has become an expected component of modern business, like the infrastructure that earlier supported expedited software development. But, we are still in the incredibly early days within this space, and the AI/ML market is expected to grow at a nearly 40% CAGR to $300B by 2026. A slew of businesses are emerging to support the management and deployment of ML models, and we’re excited to see future innovations come to market in the coming years. At LH, we’re specifically interested in tools that support model management — sharing/collaboration, debugging tools, edge case identification and other observability platforms and visualization engines — businesses that apply similar principles that programmers use to manipulate and debug code, but apply them to an ML context. We were early investors in Databand, a broader observability platform, and believe the next wave of tools will apply similar observability technology to machine learning.
