

Recently, the WSJ published a blowout exposé on pervasive fraud in the AI startup ecosystem. It got zero attention, because the hype train isn’t supposed to get derailed, but we thought the story deserved a redux. I wrote this Letter with Wayfair’s senior algorithms guru and Brandt data science lead Clayton Kim.
The thrust of Newley Purnell and Parmy Olson’s article was that tech startups, like story topic engineer.AI, frequently overstate the advancement, comprehensiveness, or business necessity of their AI. Founders stretching the truth on their technical accomplishments is nothing new. What is new — and particularly concerning to the early-stage investors who make up so much of our esteemed readership—is the unnecessary insertion of frontier technologies into irrelevant businesses for the fundraising value of buzzword recognition. We’re not going to talk about the definitional vagaries surrounding strong AI/weak AI/Machine Learning. Instead, we’re going to talk about why this fraud is so widespread, and what you can do to protect yourself without missing out on investing in what is still the most potentially impactful technological development of modern times.
Are We Investing In Businesses Or Buzzwords?
As investors, our job is to make bets on the potential of a team. It’s not to collect a portfolio that wins buzzword bingo. It can be tempting to get self-conscious about the holes in your holdings when the world catches AI, Crypto, or Cannabis fever. While it’s natural to get curious, the lowering of standards amongst professional investors in the midst of these feverish episodes is directly responsible for the glut of entrepreneurs falsely or unnecessarily claiming buzzword affiliation for their businesses.
I have talked countless entrepreneurs off this ledge, from the CEO of a content management system who wanted to claim blockchain for a raise, to the first-time GP with no technical background trying to raise a fund that only invested in strong AI. It’s a natural instinct when the capital raising landscape is so polarized towards the buzzwords.
In the Journal article, quoted sources make a big deal out of the scale requirements for functional AI. This is proffered as defense for large swathes of purportedly AI company’s business being accomplished by cheap human labor. But it’s inherently misleading. Many non-AI startups require scale before their products are viable. Any “Uber of X,” online marketplace, or social platform requires serious scale to make the product attractive.
Here’s where the unique consideration for an AI startup comes in. Is the problem they are trying to solve even feasible with machine learning? As the product scales and data are collected, does the machine increase its ability to solve the problem geometrically? If the answer to the first question is No, then it’s fraud. If the answer to the second question is “No,” then AI is a viable solution but not truly necessary or exciting.
This might sound like it exists in shades of grey, but it needn’t. A data scientist like Clayton can typically tell you how many instances of labeled training data is necessary to train a model. From there, it’s not an impossible calculation to see if the company’s user growth projections align with reality.
To Catch A Decent Ai Startup
he machine learning model itself is only a small part of the product, and thus a small part of any company you might be considering for investment. As you evaluate the model, it might be helpful for you to keep the following framework in mind: Any AI problem can be broken into three equally important subproblems: Talent, User Experience, and Data.
All of the following pull-quotes are from the WSJ Article, and generally, reference purported fraud in engineer.ai’s business practices.
-
Talent:
“Many startups typically discover that building AI is harder than expected. Among other issues, it can take years to gather data on which to train the machine-learning algorithms underpinning such technology.”
Machine learning algorithms are amazing at tackling small, discrete tasks. Complex AI products are typically a combination of several simple models, cleverly orchestrated together to deliver a good user experience. A key part of diligence on a company is examining if it has the people in place to break the problem down to tasks that machine learning can actually automate and realistically gather the data for.
“AI experts were difficult to find and hire”
With modern machine learning APIs, almost anyone can fit a machine learning model if they have clean data. Companies lacking a mature data science vision will attempt to hire individuals that can do it all: direct the AI product vision, train the models, and deploy them to production. It’s true, these types of “AI experts” are difficult to hire because they are unicorns; however, these are clearly three separate roles. A key part of being able to deliver on an AI product is to have the right talent in place that can break up a complex problem into a set of simple ones that machine learning can realistically tackle. From there, it becomes a process of engineering a good product. No machine learning algorithm will magically fix poor design.
2. User Experience:
“Several current and former employees said that some pricing and timeline calculations are generated by conventional software — not AI — and most of the work overall is performed manually by staff”
Excluding the questionable morality of calling this AI, I would argue that if this approach solves the problem, there is nothing wrong with it. AI is simply software, and we should not put it on a pedestal. Good software solves problems: does it really matter how it accomplishes it?
AI has a role to play in software: automating tasks, thereby reducing the cost (both time and money) of performing the task making these startups’ product feasible. Therefore, AI companies should be held to the same standards as any other: can they make a good product? The best AI products are invisible to the user (e.g. the image recognition in Google Photos, or Youtube’s recommendation system), they are seamless parts of good user experience.
3. Data:
“If you are telling customers that you are using AI, they will likely not expect 1950s technology. Decision trees are really old and simple technology.”
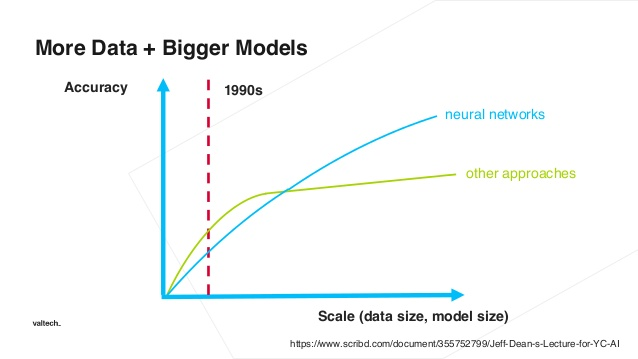
It seems unfair to call decision trees old, simple technology when Geoffrey Hinton, the godfather of neural networks, published the paper on backpropagation (the technique that makes neural networks possible) in 1986. Sure, deep learning has a few advantages over some other modeling techniques. However, these advantages come from the ability to increase performance with scale. Startups don’t typically have the scale necessary to build everything they need from scratch. However, there are techniques they can employ to capitalize on these advances in technology before having massive scale data.
“Some companies use cheap human labor as a temporary stopgap to rolling out real machine-learning algorithms, according to Mr. Crnkovic-Friis. He said that one startup he consulted — which he declined to name — told customers it was using AI software to read receipts when humans were actually doing that work.”
Typically you need thousands of human-labeled training examples before you can fit a model, and there is nothing necessarily dishonest about having humans in the loop when it comes to machine learning. A company, however, should be evaluated on its strategy here. Are they generating the right data? Are they structuring their problem correctly? Is their model being implemented intelligently?
Even building models from scratch should be viewed with scrutiny. Competent data scientists are able to fine-tune pre-existing models, which have the benefit of being trained on millions of generic data elements, by incorporating just a large handful of proprietary data. This approach can achieve surprisingly good performance before a company ever has to invest in training their own model from scratch.
